Retrieval Models
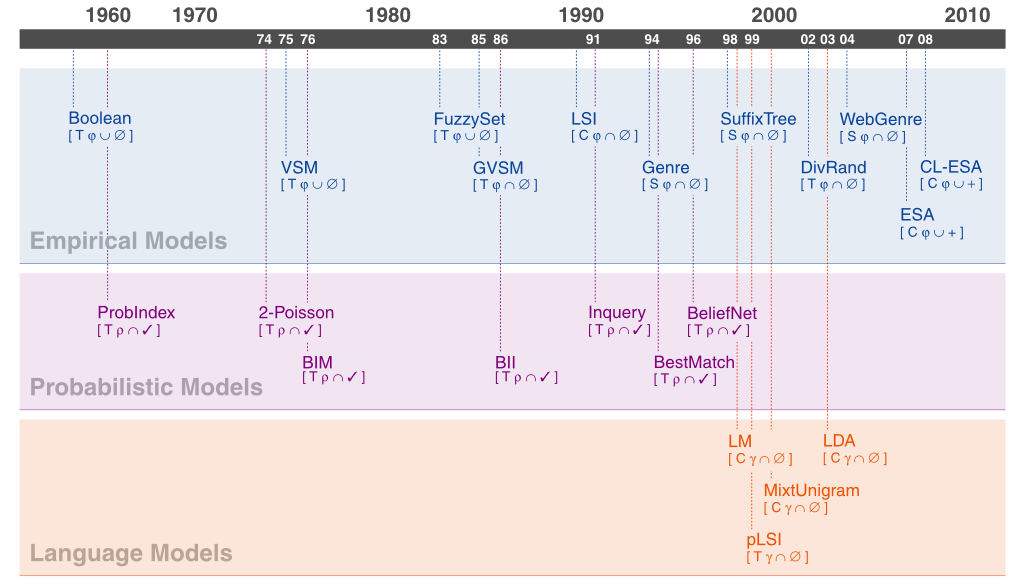
In the literature a distinction between empirical models, probabilistic models, and language models is often made, which is rooted in the query-oriented understanding of retrieval tasks but also has historical reasons. Our map reflects this distinction.
By clicking on a model acronym in the map a short description of the respective retrieval model is displayed below the map. A retrieval model is either empirical, probabilistic, or of language model type. Below a model's acronym you find a code in the form of a quadrupel, [1 2 3 4], which hints the model's characteristics along four dimensions: (1) Feature type, which defines the basic principle to capture a document's content; possible values include document terms [T], latent or explicit taxonomic concepts [C], or an (often NLP-based) method yielding special [S] features. (2) Foundation of the Retrieval status value (RSV) computation; possible values include feature vector similarity [φ], relevance [ρ] assessment, or the ability of a document to generate [γ] a query. (3) Dependency on a Closed world; possible values are open [∪], where the document collection need not to be completely given, and closed [∩], where the collection must be completely given to compute global characteristics. (4) External knowledge, if used at all; possible values include none [∅], user feedback [✓], e.g. for relevance assessment purposes, and an additional [+] document collection, e.g., for computing collection-relative document similarities. Our scheme is not intended to exactly differentiate between all particularities of a model, but shall pinpoint retrieval model strengths and weaknesses. If you find it useful, if you have hints for its improvement, or if you detect incorrect statements please drop us a mail. Finally, we kindly ask you to refer to the overview using the related publication (Stein et al., 2017).
Boolean Model
The Boolean model represents documents as a set of terms. It's underlying idea is quite intuitive: a term is either present or absent in a document. That way, term weights are all binary, and a query is just a Boolean expression; the similarity of a document to a query is either 1 (relevant) or 0 (not relevant). Drawbacks of the Boolean model include that (1) all words are equally weighted, (2) it only retrieves exact matches, and (3) no ranking on documents is possible. Even though the Boolean model is considered to be the weakest model, it is easy to understand and to implement.
G. Salton, and M.J. McGill. Introduction to Modern Information Retrieval. McGraw-Hill Book Co., New York, 1986.
Vector Space Model
The Vector Space model (VSM) represents each text document as a vector, where each dimension in the vector is associated with a single word. Because each word is treated as a single dimension, semantic information that is available in the original texts gets lost. The model not only disregards the original word order, but also synonymous and homonymous words can cause problems. For example, consider the synonyms "buy" and "purchase" that have the same meaning, but will be represented as two distinct dimensions in the vector. By contrast, a homonymous word like "crane" refers to several meanings like to a bird or to a machine, but all meanings will be mapped to a single dimension. Thus, information gets lost in both cases. The Generalized Vector Space model adresses those problems.
G. Salton, A. Wong, and C. S. Yang. A Vector Space Model for Automatic Indexing. In Commun. ACM, 18(11):613–620, 1975.
Fuzzy Set Model
In mathematics, a fuzzy set is defined as a collection of elements where the boundaries are not well-defined; they are fuzzy. Then, the Fuzzy Set model itself can be seen as an extension to the classic Boolean model. Now, each query term defines a fuzzy set of documents and each document has a degree of membership in this set instead of being just present or absent. Furthermore, classic retrieval models make the assumption that index terms are independent of each other, but in reality, that is not the case. For example, consider the two phrases "We do what we like" and "We like what we do." Hence, Fuzzy Set models utilize a term-term correlation matrix that not only maps relationships between terms, but also returns the fuzzy set of documents for a query term.
Y. Ogawa, T. Morita, and K. Kobayashi. A fuzzy document retrieval system using the keyword connection matrix and a learning method. In Fuzzy Sets and Systems, 39(2):163–179, 1991.
Generalized Vector Space Model
The Generalized Vector Space Model (GVSM) addresses the orthogonality assumption of the Vector Space Model (VSM) in information retrieval. The orthogonality assumption refers to the independence of each term in the VSM. For example, the semantic similarity between the synonyms "house" and "home" would not be treated any differently to unrelated word pairs in the VSM. The GVSM captures the semantic similarity between terms and deprecates the pairwise orthogonality assumption by introducing term to term correlations.
S. K. M. Wong, W. Ziarko, and P. C. N. Wong. Generalized Vector Spaces Model in Information Retrieval. In Proceedings of the Eighth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 18–25, Montreal, Canada, 1985.
Latent Semantic Indexing
The objective of Latent Semantic Indexing (LSI) is to overcome two problems with bag-of-words information retrieval. First, the user may specify valid synonyms of words that are not contained in relevant documents. Second, documents with matching words may be returned with alternative definitions to those intended by the user. The LSI model attempts to address these problems with a statistical approach. That is, a large matrix is used to form a "semantic space" where related term-document pairs can be organized together. Then the "singular value decomposition" mathematical technique is applied to organize the patterns in the data together.
S. C. Deerwester, S. T. Dumais, T. K. Landauer, G. W. Furnas, and R. A. Harshman. Indexing by Latent Semantic Analysis. In Journal of the American Society of Information Science, 41(6):391–407, 1990.
Genre Classification
Genre classification refers to classifying content into categories, such as press, fiction, and scholarly work. This can be applied to information retrieval to allow lists of results to be filtered according to genre. Discriminant analysis is a method from descriptive statistics that can be applied here. This method aims to develop discriminant functions using pre-categorized data on input parameters based on parts of speech, word frequencies, and language statistics. Then unseen samples can be categorized on the developed functions.
J. Karlgren and D. Cutting. Recognizing Text Genres with Simple Metrics using Discriminant Analysis. In Proceedings of the Fifteenth Conference on Computational Linguistics, pages 1071–1075, Kyoto, Japan, 1994.
SuffixTree
The suffix tree model uses a tree to represent a document where paths from the root node to a leaf node encode a word-level suffix of the document string. That way, the representation incorporates information about word order. To compare two documents, a tree similarity measure is employed that measures how many paths that start at the root node are shared between two suffix trees. The suffix tree model effectively implements a similarity assessment based on all n-grams of two documents where n ranges from 1 (as in the Vector Space model) to the length of the longer document. This suggests quadratic time and space requirements, however, suffix trees can be constructed and stored in linear time and space.
Sven Meyer zu Eißen, Benno Stein, and Martin Potthast. The Suffix Tree Document Model Revisited. In Klaus Tochtermann and Hermann Maurer, editors, Proceedings of the 5th International Conference on Knowledge Management (I-KNOW 05), Graz, Austria, Journal of Universal Computer Science, pages 596–603, July 2005. Know-Center. ISSN 0948-695x.
DivRand
Divergence from randomness models identify index terms within documents relative to a collection of documents: each term found in a document is weighted by computing a divergence score for the within-document frequency from the term's presumed probability distribution in a collection of documents. Then, the term weights are smoothed by considering a term's information gain within the subset of documents that contain the term at least once (the elite-set). For example, the term "atom" appears only in a fraction of all documents and thus sets those documents apart, however, within the physics domain it still does not carry much information about a paper's topic. Finally, the term weights are normalized regarding document length.
Gianni Amati and Cornelis Joost Van Rijsbergen. Probabilistic Models of Information Retrieval based on Measuring the Divergence from Randomness. ACM Trans. Inf. Syst. 20, 4 (October 2002), 357–389.
WebGenre
Models that aim at encoding a web page's genre rather than its topic are called Web Genre models. These models employ, among others, features related to a web page's presentation, the writing style of its contents, and vocabulary usage therein. Particularly the latter features have been found useful, since the core vocabulary of often observed terms within a particular genre differs from that of other genres.
Benno Stein and Sven Meyer zu Eißen. Retrieval Models for Genre Classification. Scandinavian Journal of Information Systems (SJIS), 20 : 1, pages 91–117, 2008. ISBN 0905-0167.
ESA
The Explicit Semantic Analysis (ESA) was introduced to compute the semantic relatedness of natural language texts. In this respect, it yields significant improvements compared to the BOW model or LSI. The ESA represents a document as a high-dimensional vector, where the dimensions quantify the pairwise similarities between the document and the documents of some reference collection (e.g., Wikipedia). The similarities are quantified under the BOW model. The relatedness of two documents is assessed by the cosine similarity between the corresponding vector representations.
E. Gabrilovich and S. Markovitch. Computing Semantic Relatedness using Wikipedia-based Explicit Semantic Analysis. In Proceedings of IJCAI 2007.
CL-ESA
The Cross-Language Explicit Semantic Analysis (CL-ESA) is a multilingual generalization of the ESA. The CL-ESA exploits a document-aligned multilingual reference collection (e.g., Wikipedia) to represent a document as a language-independent concept vector. The relatedness of two documents in different languages is assessed by the cosine similarity between the corresponding vector representations.
M. Potthast, B. Stein, and M. Anderka. A Wikipedia-Based Multilingual Retrieval Model. In Proceedings of ECIR 2008.
BII
The Binary Independence Indexing (BII) model is a variation of the BIM, and regards one document in relation to a number of queries. The probabilistic weights for the index terms of a document are estimated based on sample of queries for this document. However, the required parameters are hard to estimate in practice.
N. Fuhr. Two models of retrieval with probabilistic indexing. In Proceedings of the 9th annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR '86), pages 249–257, 1986. ACM.
2-Poisson
The 2-Poisson model is one of the earliest probabilistic retrieval models and was originally used for identifying good index terms. It's potential for computing term weights was later exploited in models such as Best Match and Divergence from Randomness. The key assumption is that the importance of a term in a document can be determined via its distribution across the whole document collection. Whereas unimportant terms, primarily stopwords, are distributed according to a Poisson distribution, important terms, so called "specialty words", appear frequently in only a few of the documents. In these "elite documents", the term is supposed to be distributed according to a (second) Poisson distribution. Therefore the model is called 2-Poisson.
S. Robertson and S. Walker. Some simple approximations to the 2-Poisson model for probabilistic weighted retrieval. In: Proceedings of the Seventeenth Annual International ACMSIGIR Conference on Research and Development in Information Retrieval (Dublin), Springer Verlag, New York 1994, pages 232–241
BIM
The Binary Independence Model (BIM) has traditionally been used with the probabilistic ranking principle; i.e., given a query, the documents are ranked by decreasing probability of relevance. BIM makes two assumptions, which allows for a practical estimation of the probability function. (1) "Binary": documents and queries are both represented under a Boolean model. (2) "Independence": terms are modeled as occurring in documents independently.
S. E. Robertson and K. Spärck Jones. Relevance weighting of search terms. In Journal of the American Society for Information Science, 27:129–146, 1976.
Probabilistic Indexing
Probabilistic Indexing was the first major presentation of a probabilistic model for information retrieval. The idea is to weight an index term of a document by the probability that an user would use this term in a query when searching for the document. Thus, given a query, the documents can be ranked with respect to their probabilities of being relevant to the query. However, the estimation of the probabilistic parameters requires to much effort for a practical investigation of the model.
M. E. Maron and J. L. Kuhns. On relevance, probabilistic indexing and information retrieval. In Journal of the Association for Computing Machinery, 7(3):216–244, 1960.
INQUERY
The INQUERY system bases on a special form of Bayesian inference networks; so called "document retrieval inference networks". These networks consist of two components: A Document Network representing a set of documents with different representation techniques, and at varying levels of abstraction. And a Query Network that represents a user's information need. Given a query, it will be converted into the query network, which is then attached to the pre-existing document network for retrieval. As a result, a belief list is returned, which contains the probability of relevance for each document.
J. P. Callan, W. Bruce Croft, and S. M. Harding. The INQUERY Retrieval System. In: Proceedings of the Third international Conference on Database and Expert Systems Applications, Springer-Verlag, 1992, pages 78–83.
BestMatch
The Okapi BM25 is a Best Match (BM) model that computes the relevance of a document to a query based on the frequencies of the query terms appearing in the document and their inverse document frequencies. Three parameters tune the influence of the document length, the document term frequency, and the query term frequency in the model.
S. E. Robertson and S. Walker. Some simple effective approximations to the 2-Poisson model for probabilistic weighted retrieval. In Proceedings of the SIGIR 1994, pages 232–241, 1994.
Beliefnet
The BeliefNet model applies the Bayes' rule using a Bayesian network to estimate the probability that a document is relevant to a query. In this context, a Bayesian network (or belief network) is a probabilistic graphical model that represents a set of topics and document features (words, phrases, etc.) and their conditional dependencies via a directed acyclic graph. The network is constructed by dividing the query into a set of constituent topics. The probabilistic dependencies between topics and document features and among topics are estimated by means of a training collection or specified by the user.
R. Fung and B. Del Favero. Applying Bayesian networks to information retrieval. Commun. ACM 38, 3, 1995.
Language Models
The language modeling approach to information retrieval, ranks a set of documents by the probability that a document generates the given query. Therefore a language model is infered for each document and it is assumed that the query terms occur independently. The core of the model is a maximum likelihood estimate of the probability of a query term under a documents term distribution.
J. M. Ponte and W. B. Croft. A Language Modeling Approach to Information Retrieval. Research and Development in Information Retrieval, pages 275–281, 1998.
pLSI
Probabilistic topic models assume that any text document can by described by a fixed amount of latent topics. Topic models then try to discover these latent topics on the basis of a generative model. Once a generative model is trained, statistical inference can be used in order to classify unseen text documents on the basis of the probability distribution over the underlying topics. In order to quantify the similarity between two text documents, the topic models generated for each document can be compared by means of the well-known Kullback-Leibler divergence. The pLSI model allows to relate each word of a text document to some topic. Hence, text documents can be composed of multiple topics. These topics are learned from documents in a test collection.
T. Hofmann. Probabilistic Latent Semantic Indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 50–57, 1999.
Mixture of Unigrams
The mixture of unigrams is another example for a generative model in the context of probabilistic topic modeling. In contrast to the pLSI model, each document is generated only by a single latent topic; the set of possible latent topics must be provided in advance. The mixture of unigrams conforms to a simple unigram language model. In order to handle unseen words, a suitable smoothing technique such as Laplace smoothing can be applied. It should be noted that the mixture of unigrams model actually equals a naïve Bayes classifier, and thus is suited for supervised classification of text documents.
K. Nigam, A. McCallum, S. Thrun, T. M. Mitchell. Text Classification from Labeled and Unlabeled Documents using EM. Machine Learning 39(2/3):103–134, 2000.
LDA
The Latent dirichlet allocation is a sophisticated generative model in the context of probabilistic topic modeling. As with the pLSI and mixture of unigrams model, LDA assumes that text documents are composed by a mixture of latent topics and that each topic consists of a probability distribution over words. This mixture is generated by sampling from a Dirichlet distribution. In contrast to the pLSI model, LDA models a smooth distribution over the latent topics. As a result, an exact inference for this model is infeasible and one has to rely on approximation techniques such as Markov Chain Monte Carlo.
D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent Dirichlet Allocation. The Journal of Machine Learning Research. 3:993–1022, 2003.
| Legend [1 2 3 4] | |
|---|---|
| (1) Feature type |
|
| (2) RSV computation |
|
| (3) Closed world |
|
| (4) External knowledge |
|